
| Version 3 (modified by Giersch, 8 years ago) (diff) |
|---|
This site is currently under construction!
General code structure
The PALM source code layout follows similar coding standards that have been developed for other community models like NEMO ocean dynamics model (http://www.nemo-ocean.eu/content/download/250/1629/file/coding_rules_OPA9.pdf). Special emphasis is given on providing extensive comment sections within the code in order to illustrate the functionality of specific model parts.
The source code is subdivided into a series of Fortran files. Most of them contain single subroutines only. These are called from the main PALM routine (palm.f90) and wherever needed. Each file features a header, containing a description and its history of modifications. The data handling between the subroutines is usually realized via Fortran modules defined in a separate file (modules.f90) instead of using parameter lists. The code contains several machine dependent segments, e.g., calls of routines from external libraries such as the Message Passing Interface (MPI, e.g., Gropp et al., 1999), the Network Common Data Form (netCDF, see http://www.unidata.ucar.edu/software/netcdf) and the Fastest Fourier Transform in the West (FFTW, see http://www.fftw.org), and which may not be available on some machines. These segments are activated/deactivated using C-preprocessor directives, which allow to compile alternative parts of the code.
Three-dimensional arrays of prognostic variables (u = u, v = v, w = w, θ = pt, qv = q, s = s, e = e and Sa = sa are stored at the last two time levels of the Runge-Kutta substeps. These arrays are declared as (e.g., the u-wind component) u(k, j, i) on the respective subdomain of each processor, including ghost point layers nbgp = 3 by default) for data exchange between the processors (see also Sect. parallelization and optimization):
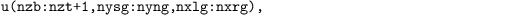
with nzb and nzt being the domain bounds of the bottom and top of the model. The lateral subdomain bounds (including ghost layers) are given by

with nys, nyn, nxl, and nxr being the true subdomain bounds in south, north, west and east direction, respectively. For optimization, most of the 3-D variables are declared as pointers, e.g., for u and v:

which speeds up the swapping of time levels after each time step, as it is not required to move the data in the memory.
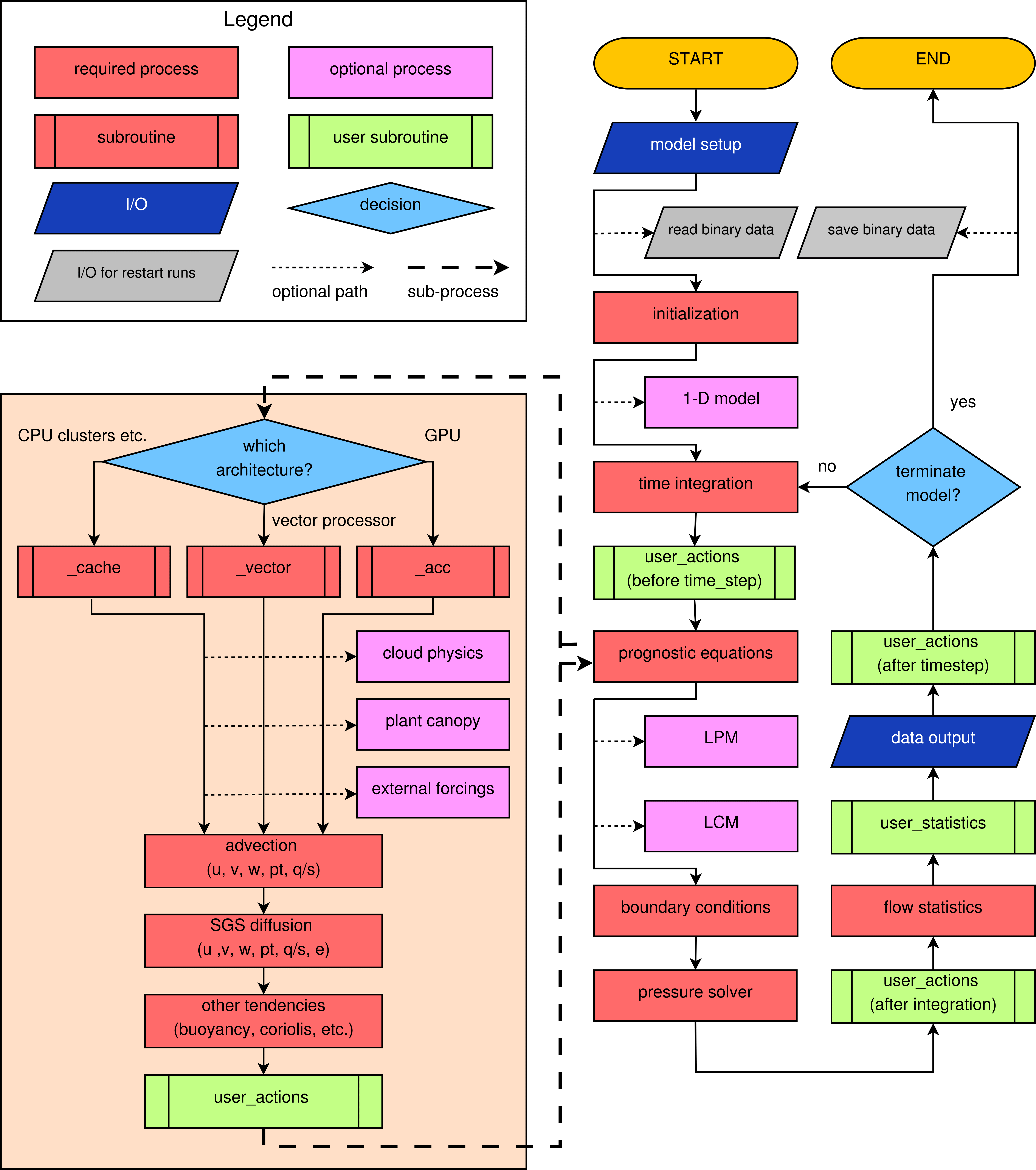
A condensed overview of the program flow of PALM is shown in the following Fig. 12.

Figure 13: Simplified flowchart of PALM.
At the beginning of the model run (hereafter referred to as "job"), the model setup is read from a Fortran NAMELIST file that is provided by the user, and optionally additional files for large-scale forcing and topography. PALM allows for conducting so-called restart jobs and job chains, where long-lasting model runs can be split into smaller ones. This does not only meet the requirements of most supercomputing systems, it also provides the user the opportunity to modify the setup between runs, or e.g., performing a set of parameter studies based on the same precursor run. For job chains, the current state of the model is saved as binary data at the end of the run and read as input for the subsequent restart run. After model initialization, possibly using a 1-D model precursor run (see Sect. 1-D model for precursor runs), the time integration loop is executed until a termination is initiated. The latter might be caused by either the fact, that the desired simulation time has been reached, or by the need to initiate a restart of the job chain. The latter can be the case when the current job is running out of CPU time, or when the user has manually forced arestart. PALM can be used on cache-optimized as well as on vector processors. Moreover, General Purpose Computing on Graphics Processing Units (GPGPU) can be used. Each machine architecture requires specially optimized code to be executed within computationally expensive loops of the prognostic equations. This is realized by a Fortran INTERFACE so that different code branches are executed in the prognostic_equations.f90 subroutine.
In most cases, the large computational grid with very large number of grid points does not allow for processing the raw model data in a post-processing step, because then the input/output (I/O) time and the required hard disc space would easily exceed the available resources. Therefore, PALM calculates many standard quantities (e.g., variances, turbulent fluxes, and even higher order moments) online during the run. Also, temporal averages of vertical profiles, cross-sections, and 3-D data can be created this way. The user interface allows the user to easily extent this output (see Sect. user interface).
After each time step it is checked whether data output (see also Sect. data handling) is required, depending on the user settings.
References
- Gropp W, Lusk E, Skjellum A. 1999. Using {MPI}: Portable Parallel Programming with the Message Passing Interface. MIT Press. Cambridge.
Attachments (1)
-
10.png
(603.1 KB) -
added by Giersch 8 years ago.
Simplified flowchart of PALM.
{kind=link}
Download all attachments as: .zip